Advertentie
We kunnen nu met bijna al onze gadgets praten, maar hoe werkt het precies? Als je vraagt: 'Welk nummer is dit?' of zeg "Call Mom", er gebeurt een wonder van moderne technologie. En hoewel het voelt alsof het op het scherpst van de snede is, gaat dit idee om met apparaten te praten decennia terug - bijna zover als jetpacks in science fiction!
Tegenwoordig wordt het grootste deel van de aandacht voor spraakgestuurde computers besteed aan smartphones. Apple, Amazon, Microsoft en Google staan aan de top van de keten, elk met zijn eigen manier om met elektronica te praten. Je weet wie ze zijn: Siri, Alexa, Cortana en het naamloze 'Ok, Google'-wezen. Wat een grote vraag oproept ...
Hoe neemt een apparaat gesproken woorden op en zet ze om in opdrachten die het kan begrijpen? In wezen komt het neer op het matchen van patronen en het maken van voorspellingen op basis van die patronen. Meer specifiek is spraakherkenning een complexe taak waar het vandaan komt Akoestische modellering en Taalmodellering.
Akoestische modellering: golfvormen en telefoons
Akoestische modellering is het proces van het nemen van een golfvorm van spraak en deze te analyseren met behulp van statistische modellen. De meest gebruikelijke methode hiervoor is Verborgen Markov-modellering, die wordt gebruikt in wat wordt genoemd uitspraak modellering om spraak op te splitsen in onderdelen die telefoons worden genoemd (niet te verwarren met echte telefoonapparaten). Microsoft is al jaren een toonaangevende onderzoeker op dit gebied.
Verborgen Markov-modellering: waarschijnlijkheidsstaten
Hidden Markov Modeling is een voorspellend wiskundig model waarbij de huidige toestand wordt bepaald door de output te analyseren. Wikipedia heeft een geweldig voorbeeld met twee vrienden.
Stel je twee vrienden voor - Lokale vriend en Externe vriend - die in verschillende steden wonen. Lokale vriend wil weten hoe het weer is waar Remote Friend woont, maar Remote Friend wil alleen praten over wat hij die dag heeft gedaan: wandelen, winkelen of schoonmaken. De waarschijnlijkheid van elke activiteit, afhankelijk van het weer van de dag.
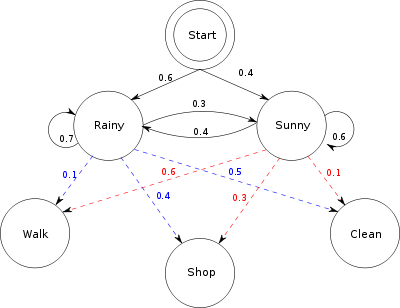
Doe net alsof dit de enige beschikbare informatie is. Hiermee kan Local Friend trends vinden in hoe het weer van dag tot dag veranderde, en met behulp van deze trends, zij kan beginnen met het maken van weloverwogen gissingen over wat het weer van vandaag zal zijn op basis van de activiteit van haar vriendin gisteren. (U kunt hierboven een diagram van het systeem zien.)
Als je een complexer voorbeeld wilt, kijk dan eens dit voorbeeld op Matlab. Bij spraakherkenning vergelijkt dit model in wezen elk deel van de golfvorm met wat er voor komt en wat erna komt, en met een woordenboek met golfvormen om erachter te komen wat er wordt gezegd.
In wezen, als je een "th" -geluid maakt, zal het dat geluid vergelijken met de meest waarschijnlijke geluiden die gewoonlijk ervoor en erna komen. Misschien betekent dat dat u moet controleren tegen het "e" -geluid, het "at" -geluid, enzovoort. Als het patroon correct overeenkomt, heeft het je hele woord. Dit is een overdreven vereenvoudiging, maar je kunt het zien De hele uitleg van Microsoft hier.
Taalmodellering: meer dan geluid
Akoestische modellering helpt je computer om je te begrijpen, maar hoe zit het met homoniemen en regionale variaties in uitspraak? Dat is waar taalmodellering in het spel komt. Google heeft op dit gebied veel onderzoek gedaan, voornamelijk door het gebruik van N-gram modellering.
Wanneer Google uw spraak probeert te begrijpen, gebeurt dit op basis van modellen die zijn afgeleid van de enorme verzameling Voice Search en YouTube-transcripties. Al die hilarisch verkeerde video-bijschriften hebben Google daadwerkelijk geholpen hun woordenboeken te ontwikkelen. Ook gebruikten ze de overledenen GOOG-411 om informatie te verzamelen over hoe mensen spreken.

Al deze taalcollectie creëerde een breed scala aan uitspraken en dialecten, wat zorgde voor een robuust woordenboek van woorden en hoe ze klinken. Dit maakt overeenkomsten mogelijk met een sterk verminderd foutenpercentage dan brute force-matching op basis van onbewerkte kansen. Je kunt een korte paper lezen hier hun methoden beschrijven.
Hoewel Google een leider is op dit gebied, worden er andere wiskundige modellen ontwikkeld, waaronder continue ruimte modellen en positionele taalmodellen, meer geavanceerde technieken die voortkomen uit onderzoek naar kunstmatige intelligentie. Deze methoden zijn gebaseerd op het repliceren van het soort redenering dat mensen doen wanneer ze naar elkaar luisteren. Deze zijn veel geavanceerder, zowel wat betreft de technologie erachter, als ook de wiskunde en programmering die nodig zijn om deze modellen in kaart te brengen.
N-Gram-modellering: waarschijnlijkheid ontmoet geheugen
N-gram modellering werkt op basis van waarschijnlijkheden, maar gebruikt een bestaand woordenboek van woorden om een vertakkende boom van mogelijkheden te creëren, die vervolgens wordt gladgestreken omwille van de efficiëntie. In zekere zin betekent dit dat N-gram-modellering veel van de onzekerheid in de eerder genoemde Hidden Markov-modellering wegneemt.
Zoals hierboven vermeld, komt de kracht van deze methode voort uit het hebben van een groot woordenboek van woorden en gebruik, niet alleen primitief geluiden. Dit geeft het programma de mogelijkheid om het verschil te zien tussen homofonen, zoals "beat" en "beet". Het is contextueel, wat betekent dat als je het hebt over de scores van gisteravond, het programma geen woorden over borsjt ophaalt.
Maar deze modellen zijn eigenlijk niet het beste voor taal, vooral vanwege problemen met de waarschijnlijkheid van woorden in langere zinnen. Naarmate je meer woorden aan een zin toevoegt, komt dit model een beetje uit, omdat het onwaarschijnlijk is dat je vroege woorden alles hebben geladen dat nodig is voor je volledige gedachte.
Het is echter eenvoudig en gemakkelijk te implementeren, waardoor het een geweldige match is voor een bedrijf als Google dat graag servers naar rekenproblemen gooit. Je kunt verder lezen op N-gram Modelieng op de universiteit van Washington, of je kunt kijken naar een lezing op Coursera.
Schreeuwen naar wolken: apps en apparaten
Iedereen die Siri heeft gebruikt, kent de frustratie van een trage netwerkverbinding. Dit komt omdat uw opdrachten naar Siri via het netwerk worden verzonden om door Apple te worden gedecodeerd. Cortana voor Windows-telefoon vereist ook een netwerkverbinding om goed te functioneren. De Echo van Amazon is daarentegen slechts een Bluetooth-luidspreker zonder internet.
Waarom het verschil? Omdat Siri en Cortana zware servers nodig hebben om uw spraak te decoderen. Kan het op je telefoon of tablet worden gedaan? Natuurlijk, maar je zou je prestaties en batterijduur tijdens dit proces doden. Het is gewoon logischer om de verwerking over te dragen aan speciale machines.
Zie het op deze manier: je commando is een auto die vastzit in de modder. Je zou het waarschijnlijk zelf met voldoende tijd en moeite naar buiten kunnen duwen, maar het zal uren duren en je uitgeput achterlaten. In plaats daarvan bel je pechhulp en halen ze je auto binnen een paar minuten tevoorschijn. Het nadeel is dat je moet bellen en op ze moet wachten, maar het is nog steeds sneller en minder belastend.
Desktopmodellen zoals Nuance hebben de neiging om lokale bronnen te gebruiken vanwege de krachtigere hardware. Immers, in de woorden van Steve Jobs, jouw desktop is een vrachtwagen. (Wat het een beetje gek maakt dat OS X gebruikt servers voor de verwerking ervan.) Dus als je taal en stem moet verwerken, is het al goed genoeg uitgerust om het zelfstandig aan te kunnen.
Aan de andere kant stelt Android ontwikkelaars in staat offline spraakherkenning op te nemen in hun apps. Google loopt graag voor op technologie en u kunt er zeker van zijn dat de andere platforms deze mogelijkheid zullen krijgen naarmate hun hardware krachtiger wordt. Niemand vindt het leuk als hun apparaat slecht wordt gedekt of slecht wordt ontvangen.
Begin nu met spraakopdrachten
Nu u de fundamentele concepten kent, moet u met uw verschillende apparaten spelen. Probeer het nieuwe uit spraakgestuurd typen in Google Documenten Hoe spraaktypen de nieuwe beste functie van Google Documenten isDe spraakherkenning is de afgelopen jaren met sprongen vooruit gegaan. Eerder deze week introduceerde Google eindelijk spraakgestuurd typen in Google Documenten. Maar is het goed? Laten wij het uitzoeken! Lees verder . Alsof het webkantoorpakket nog niet krachtig genoeg was, kunt u met spraakbesturing uw documenten volledig dicteren en opmaken. Dit breidt de krachtige technologie uit die ze al hebben ontworpen voor Chrome en Android.
Andere ideeën zijn onder meer het opzetten van uw Mac om spraakopdrachten te gebruiken Spraakopdrachten gebruiken op uw Mac Lees verder en het opzetten van uw Amazon Echo met automatisch afrekenen Hoe Amazon Echo van uw huis een smart home kan makenSmart Home Tech staat nog in de kinderschoenen, maar een nieuw product van Amazon genaamd "Echo" kan helpen om het in de mainstream te brengen. Lees verder . Leef in de toekomst en praat graag met je gadgets, zelfs als je gewoon meer papieren handdoeken bestelt. Als je een smartphone-verslaafde bent, hebben we ook tutorials voor Siri 8 dingen die u waarschijnlijk niet wist dat Siri zou kunnen doenSiri is een van de bepalende functies van de iPhone geworden, maar voor veel mensen is dit niet altijd het nuttigst. Hoewel een deel hiervan te wijten is aan de beperkingen van spraakherkenning, is de eigenaardigheid van het gebruik van ... Lees verder , Cortana 6 coolste dingen die u kunt bedienen met Cortana in Windows 10Cortana kan u helpen handsfree te gaan op Windows 10. U kunt haar uw bestanden en internet laten doorzoeken, berekeningen maken of de weersvoorspelling weergeven. Hier bespreken we enkele van haar coolere vaardigheden. Lees verder , en Android OK, Google: 20 nuttige dingen die u tegen uw Android-telefoon kunt zeggenGoogle Assistant kan u helpen veel gedaan te krijgen op uw telefoon. Hier zijn een hele reeks eenvoudige maar nuttige OK Google-opdrachten om te proberen. Lees verder .
Wat is je favoriete gebruik van stembesturing? Laat het ons weten in de comments.
Afbeeldingscredits: T-flex via Shutterstock, Terencehonles via Wikimedia Foundation, Staat Arizona, Cienpies Design via Shutterstock
Michael gebruikte geen Mac toen ze verdoemd waren, maar hij kan in Applescript coderen. Hij heeft diploma's in informatica en Engels; hij schrijft al een tijdje over Mac, iOS en videogames; en hij is al meer dan een decennium een IT-aap overdag, gespecialiseerd in scripting en virtualisatie.
