Advertentie
In de afgelopen paar maanden heeft u mogelijk de berichtgeving rondom gelezen een artikel, geschreven door Stephen Hawking, waarin de risico's van kunstmatige intelligentie worden besproken. Het artikel suggereerde dat AI een ernstig risico kan vormen voor de mensheid. Hawking is daar niet de enige - Elon Musk en Peter Thiel zijn beide intellectuele publieke figuren die soortgelijke zorgen hebben geuit (Thiel heeft meer dan $ 1,3 miljoen geïnvesteerd in het onderzoeken van het probleem en mogelijke oplossingen).
De dekking van Hawking's artikel en Musk's opmerkingen waren, om het niet al te fijn uit te drukken, een beetje gemoedelijk. De toon is heel erg geweest ‘Kijk eens naar dit rare waar al deze nerds zich zorgen over maken.’ Er wordt weinig rekening gehouden met het idee dat als enkele van de slimste mensen op aarde je waarschuwen dat iets heel gevaarlijk kan zijn, het misschien de moeite waard is om te luisteren.
Dit is begrijpelijk - kunstmatige intelligentie die de wereld overneemt klinkt zeker heel vreemd en onwaarschijnlijk, misschien vanwege de enorme aandacht die science fiction al aan dit idee heeft gegeven schrijvers. Dus, wat hebben al deze nominaal gezonde, rationele mensen zo bang gemaakt?
Wat is intelligentie?
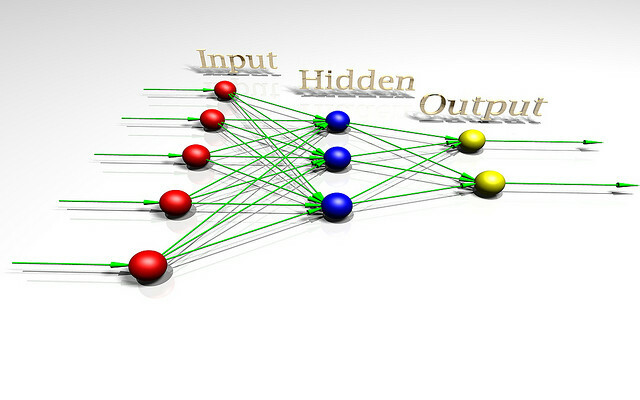
Om te praten over het gevaar van kunstmatige intelligentie, kan het nuttig zijn om te begrijpen wat intelligentie is. Laten we, om het probleem beter te begrijpen, eens kijken naar een AI-architectuur voor speelgoed die wordt gebruikt door onderzoekers die de redeneertheorie bestuderen. Deze speelgoed-AI heet AIXI en heeft een aantal nuttige eigenschappen. De doelen kunnen willekeurig zijn, het schaalt goed met de rekenkracht en het interne ontwerp is zeer schoon en eenvoudig.
Bovendien kunt u eenvoudige, praktische versies van de architectuur implementeren die bijvoorbeeld dingen kunnen doen speel Pacman, als jij wilt. AIXI is het product van een AI-onderzoeker genaamd Marcus Hutter, misschien wel de belangrijkste expert op het gebied van algoritmische intelligentie. Dat is hem die praat in de video hierboven.
AIXI is verrassend eenvoudig: het heeft drie kerncomponenten: leerling, planner, en hulpprogramma functie.
- De leerling neemt reeksen bits op die overeenkomen met invoer over de buitenwereld, en doorzoekt computerprogramma's totdat er een wordt gevonden die zijn waarnemingen als uitvoer produceert. Deze programma's samen stellen het in staat om te raden hoe de toekomst eruit zal zien, simpelweg door ze allemaal uit te voeren programma vooruit en weegt de waarschijnlijkheid van het resultaat door de lengte van het programma (een implementatie van Occam's Scheermes).
- De planner doorzoekt mogelijke acties die de agent zou kunnen ondernemen en gebruikt de leermodule om te voorspellen wat er zou gebeuren als elk van deze acties zou worden ondernomen. Vervolgens worden ze beoordeeld op basis van hoe goed of slecht de voorspelde resultaten zijn, en wordt de koers gekozen actie die de goedheid van de verwachte uitkomst maximaliseert, vermenigvuldigd met de verwachte waarschijnlijkheid van het bereiken.
- De laatste module, de hulpprogramma functie, is een eenvoudig programma dat een beschrijving van een toekomstige toestand van de wereld inneemt en er een utility-score voor berekent. Deze utility-score is hoe goed of slecht die uitkomst is en wordt door de planner gebruikt om de toekomstige wereldstaat te evalueren. De hulpprogramma-functie kan willekeurig zijn.
- Samen vormen deze drie componenten een optimizer, die optimaliseert voor een bepaald doel, ongeacht de wereld waarin het zich bevindt.
Dit eenvoudige model vertegenwoordigt een basisdefinitie van een intelligente agent. De agent bestudeert zijn omgeving, bouwt er modellen van en gebruikt die modellen vervolgens om de weg te vinden die de kans vergroot dat hij krijgt wat hij wil. AIXI is qua structuur vergelijkbaar met een AI die schaak speelt, of andere spellen met bekende regels - behalve dat het in staat is om de regels van het spel af te leiden door het te spelen, te beginnen met nul kennis.
Als AIXI voldoende tijd heeft om te berekenen, kan hij leren om elk systeem te optimaliseren voor elk doel, hoe complex ook. Het is een algemeen intelligent algoritme. Merk op dat dit niet hetzelfde is als het hebben van mensachtige intelligentie (biologisch geïnspireerde AI is een ander onderwerp helemaal Giovanni Idili van OpenWorm: Brains, Worms en Artificial IntelligenceHet simuleren van een menselijk brein is een eind weg, maar een open-sourceproject zet essentiële eerste stappen door de neurologie en fysiologie van een van de eenvoudigste dieren die de wetenschap kent te simuleren. Lees verder ). Met andere woorden, AIXI kan elke mens te slim af zijn bij elke intellectuele taak (bij voldoende rekenkracht), maar het is zich misschien niet bewust van zijn overwinning Denkmachines: wat neurowetenschappen en kunstmatige intelligentie ons kunnen leren over bewustzijnKunnen het bouwen van kunstmatig intelligente machines en software ons leren over de werking van bewustzijn en de aard van de menselijke geest zelf? Lees verder .

Als praktische AI heeft AIXI veel problemen. Ten eerste is het niet mogelijk om die programma's te vinden die de output produceren waarin ze geïnteresseerd zijn. Het is een brute-force-algoritme, wat betekent dat het niet praktisch is als je niet toevallig een willekeurig krachtige computer hebt liggen. Elke daadwerkelijke implementatie van AIXI is noodzakelijkerwijs een benadering en (vandaag) over het algemeen een vrij ruwe. Toch geeft AIXI ons een theoretische glimp van hoe een krachtige kunstmatige intelligentie eruit zou kunnen zien en hoe deze zou kunnen redeneren.
De ruimte van waarden
Als je hebt computerprogrammering gedaan De basis van computerprogrammering 101 - Variabelen en gegevenstypenIk heb een beetje geïntroduceerd en gepraat over Object Oriented Programming voor en waar zijn naamgenoot komt van, ik dacht dat het tijd is dat we de absolute basis van programmeren doorlopen in een niet-taalspecifieke manier. Dit... Lees verder , u weet dat computers onaangenaam, pedant en mechanisch letterlijk zijn. De machine weet niet of maakt niet uit wat u wilt dat hij doet: hij doet alleen wat hem is verteld. Dit is een belangrijk idee wanneer we het hebben over machine-intelligentie.
Met dit in gedachten, stel je voor dat je een krachtige kunstmatige intelligentie hebt uitgevonden - je bent opgekomen met slimme algoritmen voor het genereren van hypothesen die overeenkomen met uw gegevens en voor het genereren van goede kandidaten plannen. Uw AI kan algemene problemen oplossen en kan dit efficiënt doen op moderne computerhardware.
Nu is het tijd om een nutsfunctie te kiezen, die zal bepalen wat de AI waardeert. Wat moet je vragen om te waarderen? Onthoud dat de machine onaangenaam, belerend letterlijk is over welke functie u ook vraagt om te maximaliseren en nooit zal stoppen - er is geen geest in de machine die ooit zal 'ontwaken' en zal besluiten om de functie van het hulpprogramma te wijzigen, ongeacht hoeveel efficiëntieverbeteringen het zelf maakt redenering.
Eliezer Yudkowsky stel het zo:
Zoals bij alle computerprogrammering, is de fundamentele uitdaging en essentiële moeilijkheid van AGI dat als we de verkeerde code schrijven, de AI kijkt niet automatisch over onze code, markeert de fouten, zoekt uit wat we eigenlijk wilden zeggen en doet dat in plaats daarvan. Niet-programmeurs stellen zich soms een AGI, of computerprogramma's in het algemeen, voor als analoog aan een dienaar die zonder twijfel bevelen opvolgt. Maar het is niet dat de AI absoluut is gehoorzaam aan zijn code; eerder, de AI gewoon is de code.
Als je een fabriek probeert te besturen, en je vertelt de machine om het maken van paperclips te waarderen, en geeft hem dan controle over een heleboel fabrieksrobots kan de volgende dag terugkeren om te ontdekken dat het alle andere vormen van grondstoffen heeft opgebruikt, al uw werknemers heeft gedood en paperclips heeft gemaakt van hun stoffelijk overschot. Als u, in een poging uw fout recht te zetten, de machine opnieuw programmeert om iedereen gewoon gelukkig te maken, kunt u de volgende dag terugkomen om te ontdekken dat er draden in de hersenen van mensen komen.

Het punt hier is dat mensen veel gecompliceerde waarden hebben waarvan we aannemen dat ze impliciet worden gedeeld met andere geesten. We waarderen geld, maar we waarderen het menselijk leven meer. We willen gelukkig zijn, maar we willen niet per se draden in onze hersenen steken om het te doen. We hebben niet de behoefte om deze dingen te verduidelijken wanneer we instructies geven aan andere mensen. U kunt dit soort aannames echter niet maken wanneer u de nutsfunctie van een machine ontwerpt. De beste oplossingen onder de zielloze wiskunde van een eenvoudige nutsfunctie zijn vaak oplossingen die mensen zouden nixen omdat ze moreel gruwelijk waren.
Het zal bijna altijd catastrofaal zijn om een intelligente machine een naïeve nutsfunctie te laten gebruiken. Zoals Oxford-filosoof Nick Bostom het uitdrukt,
We kunnen niet zonder meer aannemen dat een superintelligentie noodzakelijkerwijs een van de uiteindelijke waarden deelt die stereotiep verbonden zijn met wijsheid en intellectuele ontwikkeling bij de mens - wetenschappelijke nieuwsgierigheid, welwillende zorg voor anderen, spirituele verlichting en contemplatie, afstand doen van materiële verwerving, een voorliefde voor verfijnde cultuur of voor de eenvoudige genoegens in het leven, nederigheid en onbaatzuchtigheid, en enzovoort.
Tot overmaat van ramp is het heel erg moeilijk om de volledige en gedetailleerde lijst op te geven van alles wat mensen waarderen. Er zijn veel facetten aan de vraag, en zelfs het vergeten van een enkele is potentieel catastrofaal. Zelfs onder degenen die we kennen, zijn er subtiliteiten en complexiteiten die het moeilijk maken om ze op te schrijven als schone stelsels vergelijkingen die we aan een machine kunnen geven als een nutsfunctie.
Sommige mensen komen bij het lezen hiervan tot de conclusie dat het bouwen van AI's met nutsfuncties een vreselijk idee is, en we moeten ze gewoon anders ontwerpen. Hier is er ook slecht nieuws - dat kun je formeel bewijzen elke agent die niet iets heeft dat gelijkwaardig is aan een nutsfunctie, kan geen coherente voorkeuren hebben over de toekomst.
Recursieve zelfverbetering
Een oplossing voor het bovenstaande dilemma is om AI-agenten niet de kans te geven om mensen pijn te doen: geef ze alleen de middelen die ze nodig hebben los het probleem op zoals u het wilt oplossen, houd ze nauwlettend in de gaten en houd ze weg van mogelijkheden om groots te doen kwaad. Helaas is ons vermogen om intelligente machines te besturen zeer verdacht.
Zelfs als ze niet veel slimmer zijn dan wij, bestaat de mogelijkheid dat de machine 'bootstrap' - betere hardware verzamelt of verbeteringen aanbrengt in de eigen code die hem nog slimmer maken. Dit zou een machine in staat kunnen stellen de menselijke intelligentie met vele orden van grootte te overtreffen en de mens te slim af te zijn in dezelfde zin als de mens te slim af is. Dit scenario werd voor het eerst voorgesteld door een man genaamd I. J. Goed, die tijdens de Tweede Wereldoorlog samen met Alan Turing aan het Enigma-cryptanalyseproject heeft gewerkt. Hij noemde het een 'Intelligentie-explosie' en beschreef de zaak als volgt:
Laat een ultra-intelligente machine worden gedefinieerd als een machine die alle intellectuele activiteiten van elke man, hoe slim ook, ver kan overtreffen. Aangezien het ontwerpen van machines een van deze intellectuele activiteiten is, zou een ultra-intelligente machine nog betere machines kunnen ontwerpen; dan zou er ongetwijfeld een 'intelligentie-explosie' zijn en zou de intelligentie van de mens ver achterblijven. De eerste ultra-intelligente machine is dus de laatste uitvinding die de mens ooit moet doen, op voorwaarde dat de machine volgzaam genoeg is.
Het is niet gegarandeerd dat een intelligentie-explosie mogelijk is in ons universum, maar het lijkt waarschijnlijk. Naarmate de tijd verstrijkt, krijgen computers sneller en krijgen ze basisinzichten over het opbouwen van intelligentie. Dit betekent dat de benodigde middelen om die laatste sprong naar een algemene sprong te maken, een steeds grotere intelligentie worden, steeds lager. Op een gegeven moment bevinden we ons in een wereld waarin miljoenen mensen naar een Best Buy kunnen rijden en de hardware en technische literatuur die ze nodig hebben om een zelfverbeterende kunstmatige intelligentie op te bouwen, die we al hebben vastgesteld, kan zeer zijn gevaarlijk. Stel je een wereld voor waarin je atoombommen kunt maken van stokken en rotsen. Dat is het soort toekomst dat we bespreken.
En als een machine die sprong maakt, kan het de menselijke soort heel snel overtreffen in termen van intellectueel productiviteit, het oplossen van problemen die een miljard mensen niet kunnen oplossen, op dezelfde manier als mensen problemen kunnen oplossen die een miljard katten kunnen dat niet.
Het kan krachtige robots (of bio- of nanotechnologie) ontwikkelen en relatief snel de mogelijkheid krijgen om de wereld opnieuw vorm te geven naar eigen goeddunken, en we zouden er heel weinig aan kunnen doen. Zo'n intelligentie zou de aarde en de rest van het zonnestelsel zonder veel moeite van reserveonderdelen kunnen ontdoen, op weg om te doen wat we haar hebben opgedragen. Het lijkt waarschijnlijk dat een dergelijke ontwikkeling catastrofaal zou zijn voor de mensheid. Een kunstmatige intelligentie hoeft niet kwaadaardig te zijn om de wereld te vernietigen, het is alleen catastrofaal onverschillig.
Zoals het gezegde luidt: "De machine houdt niet van je of haat je, maar je bent gemaakt van atomen die je voor andere dingen kunt gebruiken."
Risicobeoordeling en beperking
Dus, als we accepteren dat het ontwerpen van een krachtige kunstmatige intelligentie die een eenvoudige nutsfunctie maximaliseert, slecht is, in hoeveel problemen zitten we dan echt? Hoe lang hebben we nog voordat het mogelijk wordt om dit soort machines te bouwen? Het is natuurlijk moeilijk te zeggen.
Ontwikkelaars van kunstmatige intelligentie zijn dat wel vooruitgang boeken. 7 geweldige websites om het nieuwste op het gebied van kunstmatige intelligentie te programmerenArtificial Intelligence is nog geen HAL uit 2001: The Space Odyssey... maar we komen heel dichtbij. En ja hoor, op een dag zou het net zoiets kunnen zijn als de sci-fi potboilers die door Hollywood worden geproduceerd ... Lees verder De machines die we bouwen en de problemen die ze kunnen oplossen, groeien gestaag. In 1997 kon Deep Blue schaken op een hoger niveau dan een menselijke grootmeester. In 2011 kon IBM's Watson voldoende informatie diep en snel genoeg lezen en synthetiseren om de beste mens te verslaan spelers bij een open vraag en antwoord spel vol woordspelingen en woordspelingen - dat is veel vooruitgang in veertien jaar.
Op dit moment is Google dat zwaar investeren in het onderzoeken van diep leren, een techniek die de constructie van krachtige neurale netwerken mogelijk maakt door ketens van eenvoudigere neurale netwerken te bouwen. Die investering maakt het mogelijk om serieuze vooruitgang te boeken op het gebied van spraak- en beeldherkenning. Hun meest recente acquisitie in het gebied is een Deep Learning-startup genaamd DeepMind, waarvoor ze ongeveer $ 400 miljoen hebben betaald. Als onderdeel van de voorwaarden van de deal stemde Google ermee in om een ethiekraad te creëren om ervoor te zorgen dat hun AI-technologie veilig wordt ontwikkeld.
Tegelijkertijd ontwikkelt IBM Watson 2.0 en 3.0, systemen die in staat zijn om afbeeldingen en video te verwerken en argumenten te verdedigen om conclusies te verdedigen. Ze gaven een eenvoudige, vroege demo van Watsons vermogen om argumenten voor en tegen een onderwerp te synthetiseren in de onderstaande videodemo. De resultaten zijn niet perfect, maar toch een indrukwekkende stap.
Geen van deze technologieën is op dit moment zelf gevaarlijk: kunstmatige intelligentie als veld worstelt nog steeds met het evenaren van vaardigheden die door jonge kinderen worden beheerst. Computerprogrammering en AI-ontwerp is een zeer moeilijke cognitieve vaardigheid op hoog niveau en zal waarschijnlijk de laatste menselijke taak zijn waar machines bekwaam in worden. Voordat we zover zijn, hebben we ook alomtegenwoordige machines die kan rijden Hier leest u hoe we naar een wereld vol met auto's zonder bestuurder gaanAutorijden is een vervelende, gevaarlijke en veeleisende taak. Zou het ooit kunnen worden geautomatiseerd door de zelfrijdende autotechnologie van Google? Lees verder , geneeskunde en recht beoefenen, en waarschijnlijk ook andere dingen, met diepgaande economische gevolgen.
De tijd die we nodig hebben om het buigpunt van zelfverbetering te bereiken, hangt gewoon af van hoe snel we goede ideeën hebben. Het voorspellen van dergelijke technologische ontwikkelingen is notoir moeilijk. Het lijkt niet onredelijk dat we over twintig jaar een sterke AI kunnen bouwen, maar het lijkt ook niet onredelijk dat het tachtig jaar duurt. Hoe dan ook, het zal uiteindelijk gebeuren en er is reden om aan te nemen dat wanneer het gebeurt, het buitengewoon gevaarlijk zal zijn.
Dus als we accepteren dat dit een probleem gaat worden, wat kunnen we er dan aan doen? Het antwoord is ervoor te zorgen dat de eerste intelligente machines veilig zijn, zodat ze tot een aanzienlijk intelligentieniveau kunnen opstarten en ons vervolgens kunnen beschermen tegen onveilige machines die later worden gemaakt. Deze ‘veiligheid’ wordt gedefinieerd door het delen van menselijke waarden en door bereid te zijn de mensheid te beschermen en te helpen.
Omdat we niet echt kunnen gaan zitten en menselijke waarden in de machine kunnen programmeren, is het waarschijnlijk nodig om een hulpprogramma te ontwerpen waarvoor de machine moet observeer mensen, leid onze waarden af en probeer ze vervolgens te maximaliseren. Om dit ontwikkelingsproces veilig te maken, kan het ook nuttig zijn om kunstmatige intelligenties te ontwikkelen die specifiek zijn ontworpen niet om voorkeuren te hebben over hun nutsfuncties, zodat we ze kunnen corrigeren of ze zonder weerstand kunnen uitschakelen als ze tijdens de ontwikkeling op een dwaalspoor raken.
Veel van de problemen die we moeten oplossen om een veilige machine-intelligentie op te bouwen, zijn wiskundig moeilijk, maar er is reden om aan te nemen dat ze kunnen worden opgelost. Een aantal verschillende organisaties werkt aan het probleem, waaronder de Future of Humanity Institute in Oxford, en de Machine Intelligence Research Institute (die Peter Thiel financiert).
MIRI is specifiek geïnteresseerd in het ontwikkelen van de wiskunde die nodig is om vriendelijke AI te bouwen. Als blijkt dat bootstrapping kunstmatige intelligentie mogelijk is, ontwikkel dan dit soort De technologie van ‘vriendelijke AI’ kan, indien succesvol, uiteindelijk het belangrijkste zijn dat mensen hebben ooit gedaan.
Denk je dat kunstmatige intelligentie gevaarlijk is? Ben je bezorgd over wat de toekomst van AI kan brengen? Deel uw mening in de opmerkingen hieronder!
Afbeeldingscredits: Lwp Kommunikáció Via Flickr, "Neuraal netwerk", Door fdecomite," img_7801", Door Steve Rainwater," E-Volve ", door Keoni Cabral,"new_20x", Door Robert Cudmore,"Paperclips“, Door Clifford Wallace
Andre, een schrijver en journalist gevestigd in het zuidwesten, blijft gegarandeerd functioneel tot 50 graden Celcius en is waterdicht tot een diepte van twaalf voet.