Advertentie
als jij een website runnen 10 manieren om een kleine en eenvoudige website te maken zonder overkillWordPress kan een overkill zijn. Zoals deze andere uitstekende services bewijzen, is WordPress niet alles en eindigt het maken van websites. Als u eenvoudigere oplossingen wilt, kunt u kiezen uit een variëteit. Lees verder heeft u waarschijnlijk gehoord van een robots.txt-bestand (of de 'standaard voor uitsluiting van robots'). Of je het nu hebt of niet, het is tijd om erover te leren, want dit eenvoudige tekstbestand is een cruciaal onderdeel van je site. Het lijkt misschien onbeduidend, maar het zal je misschien verbazen hoe belangrijk het is.
Laten we eens kijken wat een robots.txt-bestand is, wat het doet en hoe u het correct kunt instellen voor uw site.
Wat is een robots.txt-bestand?
Om te begrijpen hoe een robots.txt-bestand werkt, moet u dit weten een beetje over zoekmachines Hoe werken zoekmachines?Voor veel mensen IS Google het internet. Het is misschien wel de belangrijkste uitvinding sinds het internet zelf. En hoewel zoekmachines sindsdien veel zijn veranderd, zijn de onderliggende principes nog steeds hetzelfde. Lees verder . De korte versie is dat ze 'crawlers' uitzenden, dit zijn programma's die het internet afzoeken naar informatie. Vervolgens slaan ze een deel van die informatie op, zodat ze mensen er later naartoe kunnen leiden.
Deze crawlers, ook wel 'bots' of 'spiders' genoemd, vinden pagina's van miljarden websites. Zoekmachines geven hen aanwijzingen over waar ze heen moeten gaan, maar individuele websites kunnen ook met de bots communiceren en hen vertellen naar welke pagina's ze moeten kijken.
Meestal doen ze eigenlijk het tegenovergestelde en vertellen ze welke pagina's ze hebben zou niet moeten naar kijken. Dingen zoals beheerpagina's, backend-portals, categorie- en tagpagina's en andere dingen die site-eigenaren niet op zoekmachines willen weergeven. Deze pagina's zijn nog steeds zichtbaar voor gebruikers en ze zijn toegankelijk voor iedereen met toestemming (wat vaak iedereen is).
Maar door die spiders te vertellen sommige pagina's niet te indexeren, doet het robots.txt-bestand iedereen een plezier. Als u op een zoekmachine naar "MakeUseOf" zocht, zou u dan willen dat onze administratieve pagina's hoog op de ranglijst verschijnen? Nee. Dat zou niemand goed doen, dus vertellen we zoekmachines om ze niet weer te geven. Het kan ook worden gebruikt om te voorkomen dat zoekmachines pagina's bezoeken die hen mogelijk niet helpen uw site in zoekresultaten te classificeren.
Kortom, robots.txt vertelt webcrawlers wat ze moeten doen.
Kunnen crawlers robots.txt negeren?
Negeren crawlers ooit robots.txt-bestanden? Ja. In feite veel crawlers Doen negeer het. Over het algemeen zijn die crawlers echter niet afkomstig van gerenommeerde zoekmachines. Ze zijn van spammers, e-mailverzamelaars en andere soorten geautomatiseerde bots Hoe u een eenvoudige webcrawler maakt om informatie van een website te halenAltijd al informatie van een website willen vastleggen? Hier leest u hoe u een crawler schrijft om door een website te navigeren en eruit te halen wat u nodig heeft. Lees verder die over het internet zwerven. Het is belangrijk om hier rekening mee te houden - het gebruik van de robotuitsluitingsnorm om bots te vertellen dat ze moeten weren, is geen effectieve beveiligingsmaatregel. Sommige bots doen dat zelfs begin met de pagina's die je zegt dat ze niet moeten gaan.
Zoekmachines doen echter wat uw robots.txt-bestand zegt, zolang het maar correct is opgemaakt.
Hoe een robots.txt-bestand te schrijven
Er zijn een paar verschillende onderdelen die in een standaardbestand voor robotuitsluiting gaan. Ik zal ze hier elk afzonderlijk opsplitsen.
Verklaring van user-agent
Voordat je een bot vertelt welke pagina's hij niet mag bekijken, moet je aangeven met welke bot je praat. Meestal gebruikt u een eenvoudige verklaring die 'alle bots' betekent. Dat ziet er zo uit:
User-agent: *De asterisk staat voor "alle bots". U kunt echter voor bepaalde bots pagina's specificeren. Om dat te doen, moet je de naam weten van de bot waarvoor je richtlijnen opstelt. Dat kan er als volgt uitzien:
User-agent: Googlebot. [lijst met pagina's die niet moeten worden gecrawld] User-agent: Googlebot-Image / 1.0. [lijst met pagina's die niet moeten worden gecrawld] User-agent: Bingbot. [lijst met pagina's die niet moeten worden gecrawld]Enzovoort. Als u een bot ontdekt die u helemaal niet op uw site wilt crawlen, kunt u dat ook specificeren.
Om de namen van user agents te vinden, ga naar useragentstring.com.
Pagina's niet toestaan
Dit is het belangrijkste onderdeel van uw robotuitsluitingsbestand. Met een simpele declaratie vertel je een bot of een groep bots om bepaalde pagina's niet te crawlen. De syntaxis is eenvoudig. U kunt als volgt toegang tot alles in de 'admin'-directory van uw site niet toestaan:
Niet toestaan: / admin /Die regel zou voorkomen dat bots uwsite.com/admin, uwsite.com/admin/login, uwsite.com/admin/files/secret.html en al het andere dat onder de beheerdersdirectory valt, kruipt.
Om een enkele pagina niet toe te staan, geeft u deze gewoon op in de niet toegestane regel:
Disallow: /public/exception.htmlNu wordt de 'uitzonderingspagina' niet getekend, maar al het andere in de map 'openbaar' wel.
Om meerdere mappen of pagina's op te nemen, vermeldt u ze gewoon op volgende regels:
Niet toestaan: / privé / Niet toestaan: / admin / Niet toestaan: / cgi-bin / Niet toestaan: / temp /Deze vier regels zijn van toepassing op de user-agent die u bovenaan de sectie heeft opgegeven.
Gebruik dit als u wilt voorkomen dat bots naar een pagina op uw site kijken:
Niet toestaan: /Verschillende standaarden instellen voor bots
Zoals we hierboven hebben gezien, kunt u bepaalde pagina's voor verschillende bots specificeren. Door de vorige twee elementen te combineren, ziet dat er als volgt uit:
User-agent: googlebot. Niet toestaan: / admin / Disallow: / private / User-agent: bingbot. Niet toestaan: / admin / Niet toestaan: / privé / Disallow: / secret /De secties 'admin' en 'privé' zijn onzichtbaar op Google en Bing, maar Google ziet de 'geheime' directory, terwijl Bing dat niet doet.
U kunt algemene regels voor alle bots specificeren door de asterisk user-agent te gebruiken en vervolgens specifieke instructies aan bots te geven in volgende secties.
Alles bij elkaar brengen
Met bovenstaande kennis kun je een compleet robots.txt-bestand schrijven. Start gewoon je favoriete teksteditor op (dat zijn we fans van Sublime 11 sublieme teksttips voor productiviteit en een snellere workflowSublime Text is een veelzijdige teksteditor en een gouden standaard voor veel programmeurs. Onze tips zijn gericht op efficiënte codering, maar algemene gebruikers zullen de sneltoetsen waarderen. Lees verder hier) en begin bots te laten weten dat ze niet welkom zijn in bepaalde delen van uw site.
Als je een voorbeeld van een robots.txt-bestand wilt zien, ga dan naar een site en voeg '/robots.txt' toe aan het einde. Hier is een deel van het bestand Giant Bicycles robots.txt:
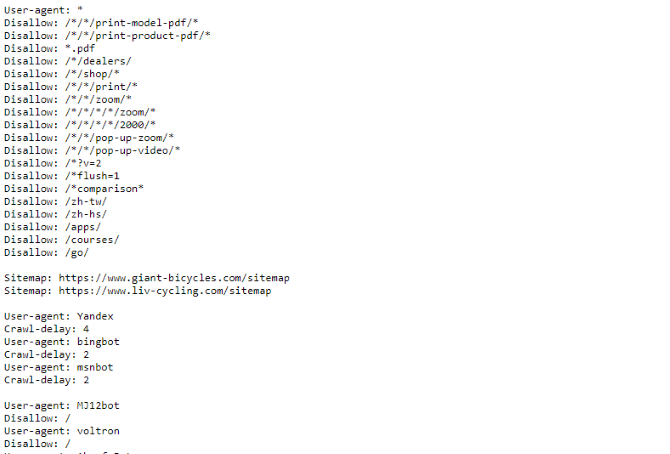
Zoals u kunt zien, zijn er nogal wat pagina's die ze niet in zoekmachines willen weergeven. Ze bevatten ook een paar dingen waar we het nog niet over hebben gehad. Laten we eens kijken wat u nog meer kunt doen in uw robotuitsluitingsbestand.
Uw sitemap lokaliseren
Als uw robots.txt-bestand bots vertelt waar niet om te gaan, je sitemap doet het tegenovergestelde Hoe u een XML-sitemap maakt in 4 eenvoudige stappenEr zijn twee soorten sitemaps: een HTML-pagina of een XML-bestand. Een HTML-sitemap is een enkele pagina die bezoekers alle pagina's op een website toont en meestal links naar die ... Lees verder , en helpt ze vinden wat ze zoeken. En hoewel zoekmachines waarschijnlijk al weten waar uw sitemap zich bevindt, kan het geen kwaad om ze opnieuw te laten weten.
De verklaring voor een sitemaplocatie is eenvoudig:
Sitemap: [URL van sitemap]Dat is het.
In ons eigen robots.txt-bestand ziet het er als volgt uit:
Sitemap: //www.makeuseof.com/sitemap_index.xmlDat is alles.
Een crawlvertraging instellen
De crawl-vertragingsrichtlijn vertelt bepaalde zoekmachines hoe vaak ze een pagina op uw site kunnen indexeren. Het wordt gemeten in seconden, hoewel sommige zoekmachines het iets anders interpreteren. Sommigen zien een crawlvertraging van 5 als een teken dat ze na elke crawl vijf seconden moeten wachten om de volgende te starten. Anderen interpreteren het als een instructie om elke vijf seconden slechts één pagina te crawlen.
Waarom zou je een crawler vertellen om niet zoveel mogelijk te crawlen? Naar bandbreedte behouden 4 manieren waarop Windows 10 uw internetbandbreedte verspiltVerspilt Windows 10 uw internetbandbreedte? Hier leest u hoe u dit kunt controleren en wat u kunt doen om het te stoppen. Lees verder . Als uw server moeite heeft om het verkeer bij te houden, kunt u een crawlvertraging instellen. Over het algemeen hoeven de meeste mensen zich hier geen zorgen over te maken. Grote sites met veel bezoekers willen misschien een beetje experimenteren.
U stelt als volgt een crawlvertraging van acht seconden in:
Kruipvertraging: 8Dat is het. Niet alle zoekmachines zullen aan uw richtlijn voldoen. Maar vragen doet geen pijn. Net als bij het niet toestaan van pagina's, kunt u verschillende crawlvertragingen instellen voor specifieke zoekmachines.
Uw robots.txt-bestand uploaden
Zodra u alle instructies in uw bestand heeft ingesteld, kunt u deze uploaden naar uw site. Zorg ervoor dat het een gewoon tekstbestand is en de naam robots.txt heeft. Upload het vervolgens naar uw site zodat het te vinden is op uwsite.com/robots.txt.
Als u een Contentmanagement systeem 10 populairste online contentmanagementsystemenDe tijd van met de hand gecodeerde HTML-pagina's en het beheersen van CSS is allang voorbij. Installeer een content management systeem (CMS) en binnen enkele minuten kunt u een website delen met de wereld. Lees verder zoals WordPress, is er waarschijnlijk een specifieke manier om dit te doen. Omdat het in elk contentmanagementsysteem verschilt, moet u de documentatie voor uw systeem raadplegen.
Sommige systemen hebben mogelijk ook online interfaces voor het uploaden van uw bestand. Hiervoor kopieert en plakt u gewoon het bestand dat u in de vorige stappen hebt gemaakt.
Vergeet niet om uw bestand bij te werken
Het laatste advies dat ik je geef is om af en toe je robotuitsluitingsbestand te bekijken. Uw site verandert en u moet mogelijk enkele aanpassingen doen. Als u een vreemde verandering in uw zoekmachineverkeer opmerkt, is het een goed idee om ook het bestand te bekijken. Het is ook mogelijk dat de standaardnotatie in de toekomst kan veranderen. Net als al het andere op uw site, is het de moeite waard om het af en toe te controleren.
Van welke pagina's sluit u crawlers uit op uw site? Heeft u enig verschil opgemerkt in het verkeer van zoekmachines? Deel uw advies en opmerkingen hieronder!
Dann is een contentstrategie- en marketingconsultant die bedrijven helpt bij het genereren van vraag en leads. Hij blogt ook over strategie en contentmarketing op dannalbright.com.