Advertentie
Gelooft u in het idee dat als iets eenmaal op internet is gepubliceerd, het voor altijd wordt gepubliceerd? Welnu, vandaag gaan we die mythe verdrijven.
De waarheid is dat het in veel gevallen heel goed mogelijk is om informatie van internet te verwijderen. Natuurlijk is er een record van webpagina's die zijn verwijderd als u zoekt op Wayback Machine, Rechtsaf? Ja, absoluut. Op de Wayback Machine zijn er records van webpagina's die vele jaren teruggaan - pagina's die je niet zult vinden met een Google-zoekopdracht omdat de webpagina niet meer bestaat. Iemand heeft het verwijderd of de website is afgesloten.
Dus je kunt er niet omheen, toch? Informatie zal voor altijd in de steen van internet worden gegraveerd, zodat generaties lang kunnen zien? Nou, niet precies.
De waarheid is dat hoewel het moeilijk of onmogelijk kan zijn om grote nieuwsverhalen die als een virus van de ene nieuwswebsite of blog naar de andere zijn verspreid, uit te roeien, het is eigenlijk vrij eenvoudig om een webpagina of meerdere webpagina's volledig te verwijderen uit alle bestaande records - om die pagina te verwijderen voor zowel zoekmachines als de
Wayback Machine Met de nieuwe Wayback-machine kunt u visueel terugreizen in internettijdHet lijkt erop dat sinds de lancering van Wayback Machine in 2001, de site-eigenaren hebben besloten om de op Alexa gebaseerde back-end weg te gooien en deze opnieuw te ontwerpen met hun eigen open source-code. Na het uitvoeren van tests met de ... Lees verder . Er is natuurlijk een addertje onder het gras, maar daar komen we op.3 manieren om blogpagina's van het net te verwijderen
De eerste methode is de methode die de meeste website-eigenaren gebruiken, omdat ze niet beter weten - gewoon webpagina's verwijderen. Dit kan gebeuren omdat u zich heeft gerealiseerd dat u dubbele inhoud op uw site heeft of omdat u een pagina heeft die u niet in zoekresultaten wilt weergeven.
Verwijder eenvoudig de pagina
Het probleem met het volledig verwijderen van pagina's van uw website is dat, aangezien u de pagina al op de netto, er zijn waarschijnlijk links van uw eigen site en externe links van andere sites naar die specifieke bladzijde. Wanneer u het verwijdert, herkent Google die pagina van u onmiddellijk als een ontbrekende pagina.
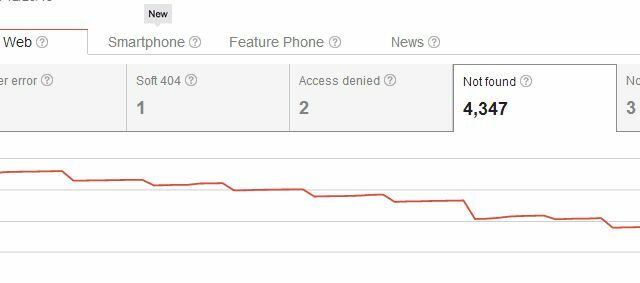
Dus door je pagina te verwijderen, heb je niet alleen een probleem met crawlfouten 'Niet gevonden' voor jezelf gemaakt, maar je hebt ook een probleem gecreëerd voor iedereen die ooit naar de pagina heeft gelinkt. Meestal zien gebruikers die via een van die externe links naar uw site gaan, uw 404-pagina, en dat is geen groot probleem, als je zoiets als de aangepaste 404-code van Google gebruikt om gebruikers nuttige suggesties te geven of alternatieven. Maar je zou denken dat er elegantere manieren zijn om pagina's uit zoekresultaten te verwijderen zonder al die 404's te starten voor bestaande inkomende links, toch?
Nou, die zijn er.
Verwijder een pagina uit de zoekresultaten van Google
Allereerst moet u begrijpen dat als de webpagina die u uit de zoekresultaten van Google wilt verwijderen, geen pagina van uw eigen site is, dan heeft u pech tenzij er juridische redenen zijn of als de site uw persoonlijke informatie online heeft geplaatst zonder uw toestemming. Als dat het geval is, gebruik dan die van Google probleemoplosser voor verwijdering om een verzoek in te dienen om de pagina uit de zoekresultaten te laten verwijderen. Als je een geldige case hebt, kan het zijn dat je enig succes zult hebben met het verwijderen van de pagina - natuurlijk heb je misschien zelfs nog meer succes contact opnemen met de website-eigenaar Hoe valse persoonlijke informatie op het internet te verwijderenOnline privacy is niet meer gegarandeerd. Leer hoe u een website kunt melden en persoonlijke informatie van internet kunt verwijderen. Lees verder zoals ik beschreef hoe ik dat in 2009 moest doen.
Als de pagina die u uit de zoekresultaten wilt verwijderen zich op uw eigen site bevindt, heeft u geluk. Het enige wat je hoeft te doen is een robots.txt bestand en zorg ervoor dat u de specifieke pagina die u niet wilt in de zoekresultaten of de hele directory met de inhoud die u niet wilt laten indexeren, heeft geweigerd. Zo ziet het blokkeren van een enkele pagina eruit.
User-agent: * Disallow: /my-deleted-article-that-i-want-removed.html
U kunt als volgt voorkomen dat bots volledige mappen van uw site doorzoeken.
User-agent: * Disallow: / content-about-personal-stuff /
Google heeft een uitstekende ondersteuningspagina waarmee u een robots.txt-bestand kunt maken als u er nog nooit een heeft gemaakt. Dit werkt buitengewoon goed, zoals ik onlangs heb uitgelegd in een artikel over het structureren van syndicatie-deals Hoe syndicatie-deals te onderhandelen en uw zoekrangschikking te beschermenSyndiceren is tegenwoordig een rage. Maar plotseling merk je dat de syndicatiepartner hoger staat dan jij in de zoekresultaten voor een verhaal dat je oorspronkelijk hebt geschreven! Bescherm uw zoekrangschikking. Lees verder zodat ze u geen pijn doen (syndicatiepartners vragen om het indexeren van hun pagina's niet toe te staan waar u wordt gesyndiceerd). Zodra mijn eigen syndicatiepartner ermee instemde om dit te doen, verdwenen de pagina's met dubbele inhoud van mijn blog volledig uit de zoekresultaten.
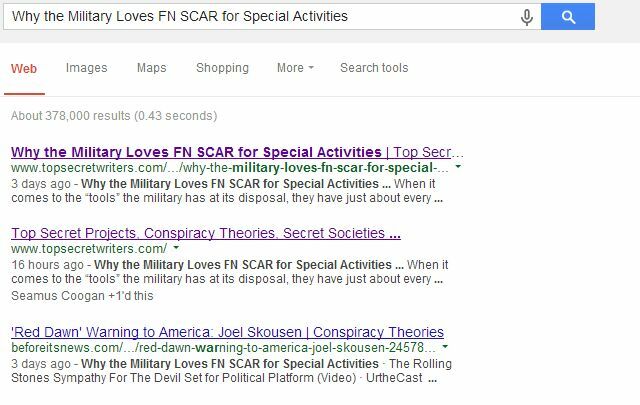
Alleen de hoofdwebsite komt op de derde plaats voor de pagina waar ze onze titel vermelden, maar mijn blog staat nu op de eerste en tweede plek; iets dat bijna onmogelijk zou zijn geweest als een website met een hogere autoriteit de dubbele pagina had geïndexeerd.
Wat veel mensen niet beseffen, is dat dit ook mogelijk is met het Internet Archive (de Wayback Machine). Hier zijn de regels die u aan uw robots.txt-bestand moet toevoegen om dit mogelijk te maken.
User-agent: ia_archiver. Disallow: / sample-category /
In dit voorbeeld vertel ik het internetarchief om alles in de voorbeeldcategorie-submap op mijn site te verwijderen van de Wayback-machine. Het internetarchief legt uit hoe u dit kunt doen op hun Help-pagina over uitsluiting. Hier leggen ze ook uit dat "Het internetarchief niet geïnteresseerd is in het aanbieden van toegang tot websites of andere internetdocumenten waarvan de auteurs hun materiaal niet in de collectie willen hebben."
Dit druist in tegen de algemene opvatting dat alles dat op internet wordt gepost voor eeuwig in het archief wordt meegesleurd. Nee - webmasters die eigenaar zijn van de inhoud kunnen de inhoud specifiek uit het archief laten verwijderen met behulp van de robots.txt-benadering.
Verwijder een individuele pagina met metatags
Als u maar een paar afzonderlijke pagina's heeft die u uit de zoekresultaten van Google wilt verwijderen, hoeft u eigenlijk de robots.txt-benadering niet te gebruiken helemaal niet, u kunt eenvoudig de juiste metatag "robots" aan de afzonderlijke pagina's toevoegen en de robots vertellen dat ze de links over de hele bladzijde.
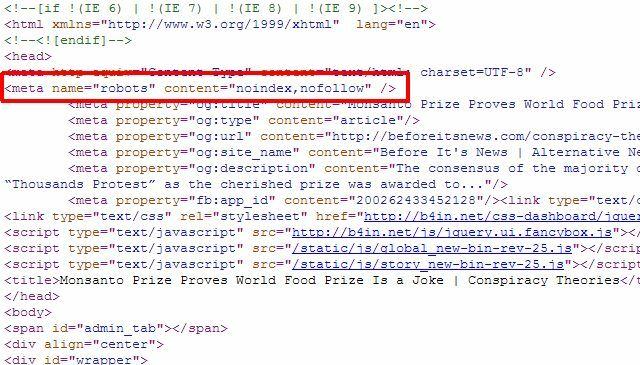
U kunt de bovenstaande meta-robots gebruiken om te voorkomen dat robots de pagina indexeren, of u kunt de Google-robot specifiek vertellen niet te indexeren, zodat de pagina alleen uit de zoekresultaten van Google wordt verwijderd en andere zoekrobots nog steeds toegang tot de pagina kunnen krijgen inhoud.
Het is helemaal aan jou hoe je wilt beheren wat robots met de pagina doen en of de pagina wel of niet wordt vermeld. Voor slechts een paar individuele pagina's is dit misschien de betere aanpak. Gebruik de robots.txt-methode om een volledige map met inhoud te verwijderen.
Het idee om inhoud te "verwijderen"
Dit soort zet het hele idee van "inhoud van internet verwijderen" op zijn kop. Technisch gezien, als u al uw eigen links naar een pagina op uw site verwijdert en u verwijdert deze uit Google Zoeken en de Internetarchief met behulp van de robots.txt-techniek, de pagina is voor alle doeleinden en doeleinden van internet verwijderd. Het leuke is echter dat als er bestaande links naar de pagina zijn, die links nog steeds werken en je geen 404-fouten voor die bezoekers zult veroorzaken.
Het is een 'zachtere' manier om inhoud van internet te verwijderen zonder de bestaande linkpopulariteit van uw site op het internet volledig te verpesten. Uiteindelijk is het aan u, maar altijd, hoe u beheert welke inhoud wordt verzameld door zoekmachines en het internetarchief onthoud dat ondanks wat mensen zeggen over de levensduur van dingen die online worden geplaatst, het echt volledig binnen uw bereik ligt controle.
Ryan heeft een BSc-graad in elektrotechniek. Hij heeft 13 jaar in automatiseringstechniek gewerkt, 5 jaar in IT en is nu een Apps Engineer. Hij was een voormalig hoofdredacteur van MakeUseOf, hij sprak op nationale conferenties over datavisualisatie en was te zien op nationale tv en radio.
