De weg om een bekwame en succesvolle programmeur te worden is moeilijk, maar zeker haalbaar. Datastructuren zijn een kerncomponent die elke programmeerstudent moet beheersen, en de kans is groot dat je al een aantal basisdatastructuren zoals arrays of lijsten hebt geleerd of ermee hebt gewerkt.
Interviewers geven er de voorkeur aan om vragen te stellen met betrekking tot datastructuren, dus als u zich voorbereidt op een sollicitatiegesprek, moet u uw kennis van datastructuren opfrissen. Lees verder, want we zetten de belangrijkste datastructuren voor programmeurs en sollicitatiegesprekken op een rij.
Gelinkte lijsten zijn een van de meest elementaire datastructuren en vaak het startpunt voor studenten in de meeste cursussen over datastructuren. Gelinkte lijsten zijn lineaire gegevensstructuren die sequentiële gegevenstoegang mogelijk maken.
Elementen binnen de gekoppelde lijst worden opgeslagen in individuele knooppunten die zijn verbonden (gekoppeld) met behulp van pointers. U kunt een gekoppelde lijst zien als een keten van knooppunten die via verschillende wijzers met elkaar zijn verbonden.
Verwant: Een inleiding tot het gebruik van gelinkte lijsten in Java
Voordat we ingaan op de details van de verschillende soorten gelinkte lijsten, is het cruciaal om de structuur en implementatie van de individuele node te begrijpen. Elk knooppunt in een gekoppelde lijst heeft ten minste één aanwijzer (dubbel gekoppelde lijstknooppunten hebben twee aanwijzers) die het verbindt met het volgende knooppunt in de lijst en het gegevensitem zelf.
Elke gekoppelde lijst heeft een kop- en staartknooppunt. Enkelvoudig gekoppelde lijstknooppunten hebben slechts één aanwijzer die naar het volgende knooppunt in de keten verwijst. Naast de volgende aanwijzer hebben dubbel gekoppelde lijstknooppunten nog een aanwijzer die naar het vorige knooppunt in de keten wijst.
Interviewvragen met betrekking tot gekoppelde lijsten draaien meestal om het invoegen, zoeken of verwijderen van een specifiek element. Invoegen in een gekoppelde lijst kost O(1) tijd, maar verwijderen en zoeken kan in het ergste geval O(n) tijd kosten. Dus gekoppelde lijsten zijn niet ideaal.
2. Binaire boom
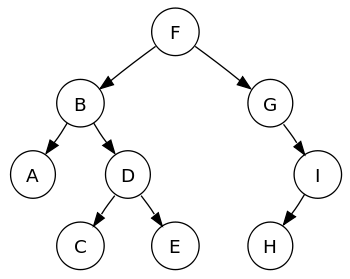
Binaire bomen zijn de meest populaire subset van de gegevensstructuur van de boomfamilie; elementen in een binaire boom zijn gerangschikt in een hiërarchie. Andere soorten bomen zijn AVL, rood-zwart, B-bomen, enz. Knooppunten van de binaire boom bevatten het data-element en twee verwijzingen naar elk kindknooppunt.
Elk bovenliggend knooppunt in een binaire boom kan maximaal twee onderliggende knooppunten hebben, en elk onderliggend knooppunt kan op zijn beurt een bovenliggend knooppunt zijn voor twee knooppunten.
Verwant: Een beginnershandleiding voor binaire bomen
Een binaire zoekboom (BST) slaat gegevens op in een gesorteerde volgorde, waarbij elementen met een sleutelwaarde kleiner dan de bovenliggende knooppunt worden aan de linkerkant opgeslagen en elementen met een sleutelwaarde die groter is dan het bovenliggende knooppunt worden opgeslagen op de Rechtsaf.
Binaire bomen worden vaak gevraagd in interviews, dus als je je voorbereidt op een interview, moet je weten hoe je een binaire boom plat maakt, een specifiek element opzoekt en meer.
3. Hashtabel
Hash-tabellen of hash-kaarten zijn een zeer efficiënte gegevensstructuur die gegevens in een array-indeling opslaat. Elk gegevenselement krijgt een unieke indexwaarde toegewezen in een hashtabel, wat efficiënt zoeken en verwijderen mogelijk maakt.
Het proces van het toewijzen of toewijzen van sleutels in een hash-kaart wordt hashing genoemd. Hoe efficiënter de hashfunctie, hoe beter de efficiëntie van de hashtabel zelf.
Elke hashtabel slaat gegevenselementen op in een waarde-indexpaar.
Waarde de gegevens zijn die moeten worden opgeslagen en index het unieke gehele getal is dat wordt gebruikt om het element in de tabel toe te wijzen. Hashfuncties kunnen zeer complex of zeer eenvoudig zijn, afhankelijk van de vereiste efficiëntie van de hashtabel en hoe u botsingen oplost.
Botsingen treden vaak op wanneer een hashfunctie dezelfde afbeelding voor verschillende elementen produceert; hash-kaartbotsingen kunnen op verschillende manieren worden opgelost, met behulp van open adressering of chaining.
Hash-tabellen of hash-kaarten hebben verschillende toepassingen, waaronder cryptografie. Ze zijn de datastructuur van de eerste keuze wanneer invoegen of zoeken in constante O(1) tijd vereist is.
4. Stapels
Stacks zijn een van de eenvoudigere gegevensstructuren en zijn vrij eenvoudig te beheersen. Een stapelgegevensstructuur is in wezen elke echte stapel (denk aan een stapel dozen of platen) en werkt op een LIFO-manier (Last In First Out).
De LIFO-eigenschap van Stacks betekent dat het element dat u het laatst hebt ingevoegd als eerste wordt geopend. U kunt geen toegang krijgen tot elementen onder het bovenste element in een stapel zonder de elementen erboven te laten knappen.
Stacks hebben twee primaire bewerkingen: push en pop. Push wordt gebruikt om een element in de stapel te plaatsen en pop verwijdert het bovenste element van de stapel.
Ze hebben ook tal van handige toepassingen, dus het is heel gebruikelijk voor interviewers om vragen te stellen met betrekking tot stapels. Weten hoe een stapel moet worden omgekeerd en uitdrukkingen moeten worden geëvalueerd, is vrij essentieel.
5. Wachtrijen
Wachtrijen zijn vergelijkbaar met stapels, maar werken op een FIFO-manier (First In First Out), wat betekent dat u toegang hebt tot de elementen die u eerder hebt ingevoegd. De wachtrijgegevensstructuur kan worden gevisualiseerd als elke echte wachtrij, waar mensen worden gepositioneerd op basis van hun volgorde van aankomst.
Het invoegen van een wachtrij wordt enqueue genoemd, en het verwijderen/verwijderen van een element aan het begin van de wachtrij wordt dequeuing genoemd.
Verwant: Een beginnershandleiding voor het begrijpen van wachtrijen en prioriteitswachtrijen
Prioriteitswachtrijen zijn een integrale toepassing van wachtrijen in veel vitale toepassingen zoals CPU-planning. In een prioriteitswachtrij worden elementen gerangschikt volgens hun prioriteit in plaats van de volgorde van aankomst.
6. Hoopjes
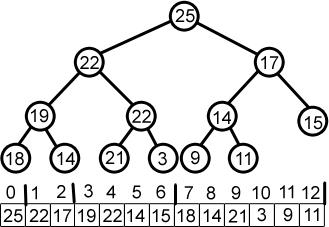
Hopen zijn een soort binaire boom waarin knooppunten in oplopende of aflopende volgorde zijn gerangschikt. In een Min Heap is de sleutelwaarde van de parent gelijk aan of kleiner dan die van de onderliggende, en het rootknooppunt bevat de minimumwaarde van de hele heap.
Evenzo bevat het hoofdknooppunt van een Max Heap de maximale sleutelwaarde van de heap; u moet de eigenschap min/max heap gedurende de hele heap behouden.
Verwant: Hoop vs. Stacks: wat onderscheidt ze?
Heaps hebben tal van toepassingen vanwege hun zeer efficiënte karakter; in de eerste plaats worden prioriteitswachtrijen vaak geïmplementeerd via heaps. Ze zijn ook een kerncomponent in heapsort-algoritmen.
Leer datastructuren
Datastructuren kunnen in het begin schrijnend lijken, maar besteed er voldoende tijd aan, en u zult ze gemakkelijk vinden.
Ze zijn een essentieel onderdeel van programmeren en voor bijna elk project moet u ze gebruiken. Weten welke datastructuur ideaal is voor een bepaald scenario is van cruciaal belang.
Deze algoritmen zijn essentieel voor de workflow van elke programmeur.
Lees volgende
- Programmeren
- Gegevensanalyse
- Codeertips

Fahad is een schrijver bij MakeUseOf en studeert momenteel informatica. Als een fervent tech-schrijver zorgt hij ervoor dat hij op de hoogte blijft van de nieuwste technologie. Hij is vooral geïnteresseerd in voetbal en technologie.
Abonneer op onze nieuwsbrief
Word lid van onze nieuwsbrief voor technische tips, recensies, gratis e-boeken en exclusieve deals!
Klik hier om je te abonneren